This post is inspired by two things. First, according to a recent study by Magna Publications, half of academics report that they work harder than they did five years ago. I have no bone to pick with Magna, which produces the very helpful Faculty Focus articles on teaching in higher education. And their survey approach is not unusual. I have filled a few surveys of the kind they seem to have used, by perfectly competent and reasonable people. In fact, one could argue it’s thanks to surveys like theirs that we’ve made a lot of progress in finding systematic discrepancies in faculty lives, among genders and races, for example. But asking people if they “think” or “feel” they are working harder than five years is to invite all sorts of problems. It’s well known we are pretty bad at evaluating the past (or the future) reliably.
The second inspiration comes from a blog post by Steven Wolfram, the creator of Mathematica and a precursor of the “quantified self” movement. Wolfram had tracked his email traffic since 1989 and decided to do a bunch of analyses on his work patterns, overall busyness, and the like.
For a modern white-collar worker, not just Wolfram, email is likely a reasonable proxy for how busy he or she is. I’m sure there is variance between professions (how effing backward can physicians really be on modern communication tools?) and individuals (I am pretty anal at replying to all email sent directly to me, usually within a few hours). For academics, I would argue, the email we send is a good indicator of work, especially of the “how busy am I?” dimension. (Nobody ever says, “I was so friggin’ busy today: I got to work on my article all day without any interruptions.”)
Wolfram’s analyses were cool (to me, at least) and possibly creepy (to many of you), but it inspired me to try something similar. I have used email since 1987, but I’ve only tracked it regularly since 1998. Unfortunately, due to data incompatibilities (and an unfortunate detour to Microsoft products), I have a solid record only since 2004. Even that record has some problems, but before I discuss them, let’s look at the data:

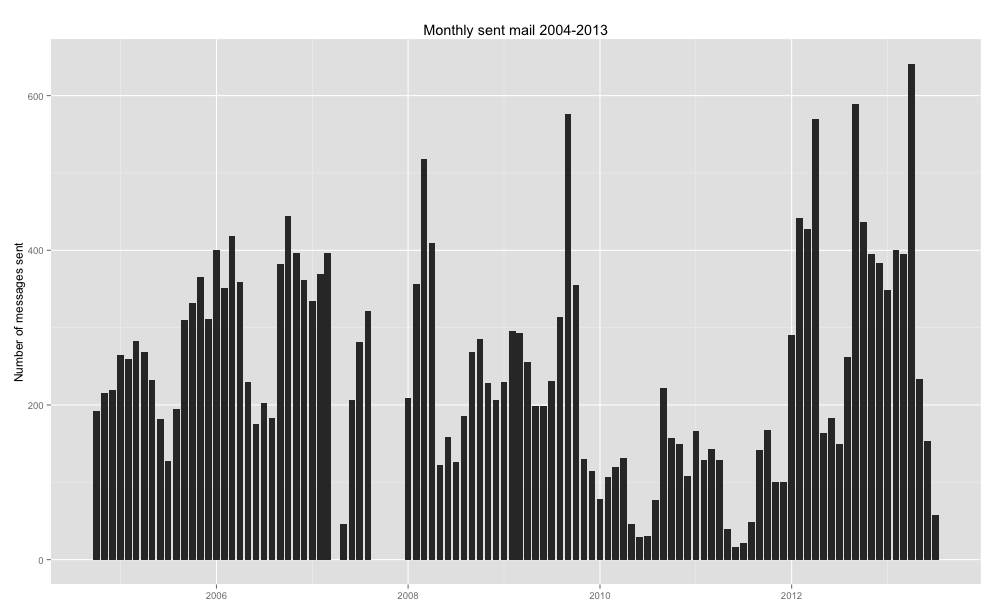
Monthly sent mail totals.
Here’s how many emails I sent each month. The total is is 24, 861 message between late 2004 and last week. The highest month is 641 messages. You’ll notice a couple of things right away:
- There are gaps in 2007. That’s just missing data; my record-keeping system has been imperfect. (That’s when I got tenure, but I did not stop using email. I was probably just more careless about my quarterly archiving.)
- 2011 seems awfully light. What happened? What happened was that I messed the setting on my laptop, so that my sent mail on that computer didn’t get tracked. For 2011, all you see are the messages I sent from my office computer.
So that little technical snafu makes it kind of pointless to do descriptive statistics such as daily or monthly averages and standard deviations. (I have them if you want, though.) But you can eyeball the data: summers are obviously lighter, and my sabbatical, academic year 2008-2009, is also lighter, but not dead. There is a slight upward trend, but the most noticeable thing are the whopper months, especially after tenure. So if I had to fill out a survey that asks, “Are you busier now than you were five years ago,” the crunch of February through April (I was grad admissions director, so it was busy) might loom large, and I might say, “Yes!” even though it’s not that much worse.
See, if I look my daily email habits, following Wolfram, I see pretty much the same pattern: I send emails all of my waking hours:

Daily email sending practices, by time of day.
On the x axis here are individual days, on the y axis is the time of day when the message was sent. (Each dot is a message.) I have not pulled an all-nighter since my first year of grad school; the seeming night-time messages are from travels in different time zones. Now you see that, indeed, around 2011 I only kept messages sent from my office machine. I work through the day, but I only go to the office during bourgeois working hours.
The key point I want to make, though, is that even with its gaps, this data is better than a rough sense of how I might feel. Of course, I don’t want to generalize from my experience to that of any other academic. So, on what basis do you say you are busier now than you were five years ago?
Nerd section:
How did I get the data? I’ve archived all my email; the post-2004 email was all on Apple Mail. I used an Applescript script to scrape all those almost 25,000 messages into a CSV file, with time stamps, and then I played with R to analyze it. Thanks to Cait Holman and David Cottrell for help with the technical stuff.