Back in the 1990s, I used to do a noncompetitive martial art. It was so much fun that I almost dropped out of grad school to become an instructor. It also had its unfun aspects, which is why I’m not doing it anymore. What I want to talk about here is the noncompetitive aspect. What do you think was the effect of this egalitarian, non-selfish aspect? At our school, at least, among the serious practitioners, at least, everything became a competition. Not only did everyone compete on the mat, in every practice (“Ha, bastard, let me show you how much better my technique is!” “No, loser, it’s not about technique but about whether I can throw you. Watch!”) but off the mat, too (“Jack is not as loyal to the chief instructor as Jill.”).![]()
After I quit the martial art, I started running competitively. I loooved racing. It turned out I was relatively good, so I would place pretty well in smaller races or in the age groups of bigger ones. That’s a great discovery when you grew up as a non-athletic klutz. I also liked competition. But the most interesting fact was that, among my training buddies, there was none of that creepy competitiveness my martial arts school had had. Except for the occasional macho jackass who didn’t know the difference between races and training, we trained hard but totally noncompetitively. After all, we had the actual races to see who could do what.

The author in Hopkington with some friends, before his fifth Boston Marathon.
It was also interesting to notice that the jackasses for whom every practice was a race actually didn’t do so well.
Being competitive is good in some instances and not so good at others. This is familiar to all athletes who have reflected on their practice. You can also draw a broader theoretical observation: the rules with which an institution operates might foster the behaviors it values and wants to promote — or do the very opposite. A competitive sport helped foster a collaborative training practice for me and my friends, which improved everyone’s performance. A vague ideology of noncompetition in the martial art helped foster insidious competition in which sniping, griping, and back-biting flourished and progress was random.
* * *
The first reading in my Introduction to Political Theory is a cool essay by Louis Menand on the purpose of college. Although it’s not formally a piece of political theory, it works like one: it takes a step back from a familiar institution — American higher education in this case — and explores theoretically the goals and values that institution tries to foster. One of Menand’s points is that, since 1945, American higher education has embraced two very different theories, meritocracy (use college as a sorting mechanism to identify the talented, the mediocre, and the untalented) and democracy (make sure all graduates have the skills and talents democratic citizenship requires).
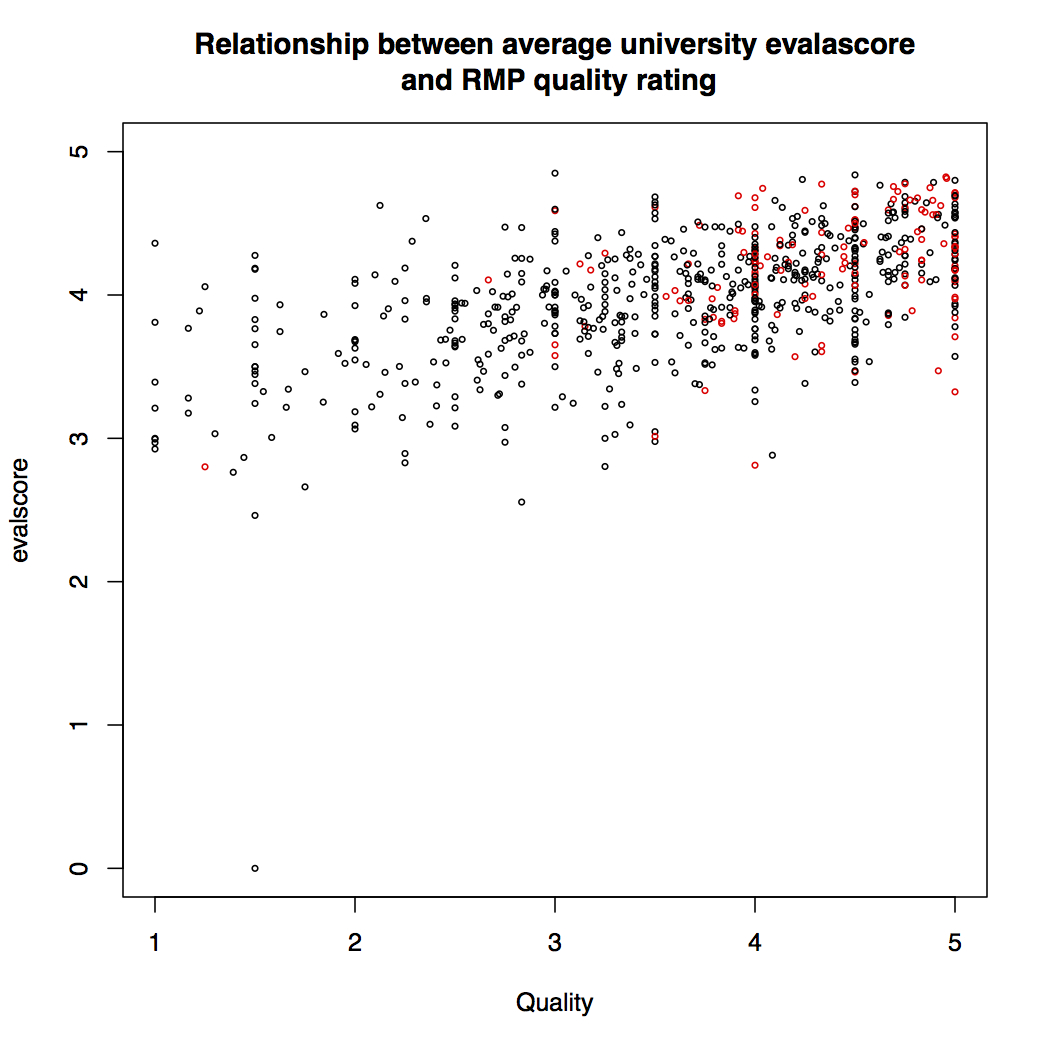
Menand doesn’t spend very much time on what kinds of behaviors higher education fosters internally. This is not a complaint; it’s not a central part of his argument. But it is related, so it’s worth asking questions about one of the most importance incentive mechanisms of education: grading.
Educational institutions don’t, for the most part, explicitly aim at competition between students. But depending on their assessment systems, some implicitly do. The most obvious case is ranking, which is still frequently done in law schools. It’s not surprising. Law schools are a kind of a pedagogical North Korea (totally backward, but in a cheerful denial about it): their use of one-time, high-stakes instruments for assessment and the Socratic Method already prove that. The ranking approach is the most insidious one, as it creates incentives not only to compete with your peers, but to actively hurt them. Come to Law School — We’ll turn you into pedagogical Tonya Hardings!
But law schools aren’t the only offenders. Even something like grading on a curve can foster perversely competitive tendencies — while simultaneously demotivating effort at learning. Now “grading on a curve” can mean a couple of different things. It can simply mean setting the median grade in an assessment instrument, but not really caring about what the distribution should be. Or it can mean making sure the shape of the resulting distribution is that familiar bell-shape.

Is this the distribution of your students? In every class? Every section? Regardless of where you teach? Amazing!
Or other related things. The problem with each of those is that it either (a) assumes students in a class are always, for the most part, just like students in another iteration of the class or (b) insists that, regardless of what the students in a course are like, their final outcome should make them look like students in other iterations of the course. In other words, (a) you’ll always think you have some really weak students, some really strong students, and lots of middle-of-the-road students or (b) you think that no matter what the distribution of talent in your course, they should look like a random sample of few weak, few strong, and lots of middling types. I’ll admit, sure, it’s possible students are similar, but you’ll need data independent of your assessment instrument to show it. Good luck with that! It can be done, but I’ll bet dollars to donuts most of the folks who grade on a curve haven’t done their homework on this. So, on either option, it seems ill-motivated.
And meanwhile, students have incentives to compete, in the bad way I experienced in my martial arts school. If the median is set beforehand, making sure others do worse than you will help you. And if the course insists on a normal distribution, it sends a totally perverse signal to everyone that everyone aspiring to do their best and actually doing well is impossible. Should it be?